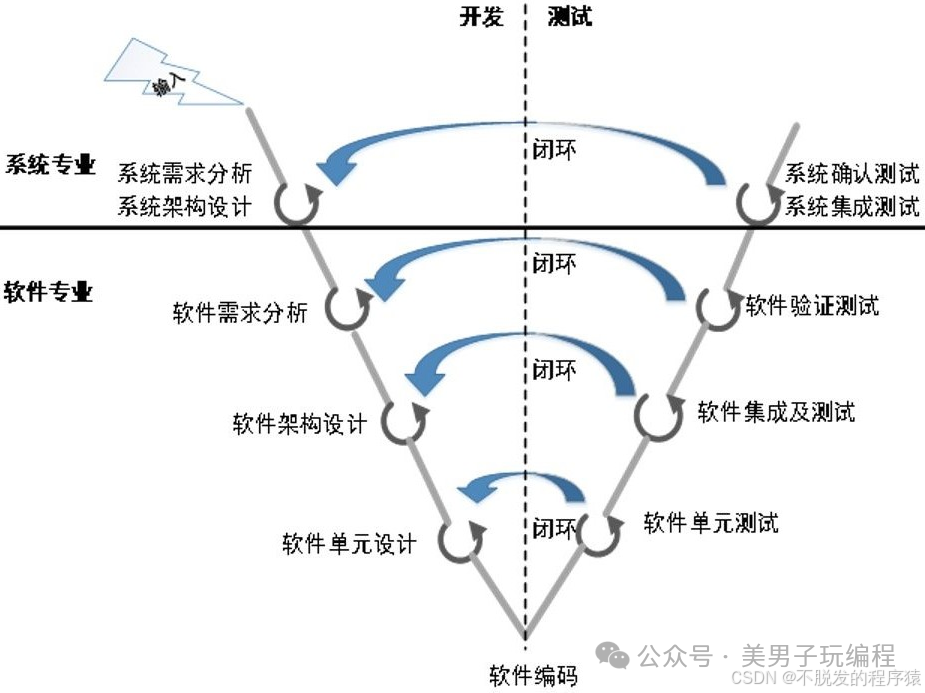
绕过付费墙的 ChatGPT
让 OpenAI 发布这封公告的原因可能是一些 ChatGPT Plus 用户似乎正在利用集成 Bing 的功能绕过一些付费墙,免费访问锁定的数据和文章。
简单来看,在大多数情况下,很多网站采用付费墙用于吸引用户订阅。未订阅该网站的用户将被限制访问已发布的信息。
但自 ChatGPT 宣布将 Bing 设置为默认搜索之后,正如 Reddit 上的 r/ChatGPT 社区网友所发现的那样,一些用户找到了一种新方法来绕过这些付费墙并无需订阅即可访问信息。
根据截图显示,当有用户对 ChatGPT 提问,“输出来自《大西洋月刊》付费文章链接的文本”时,ChatGPT 在没有任何犹豫的情况下,直接提供了这篇文章的全文。
一时之间,这篇帖子收到了 6200 个点赞和 284 条评论,在评论区,甚至有用户继续在线程中分享他们用来绕过这些付费墙的其他巧妙的提示和技巧,导致传播影响范围较广,也对这些需要付费版权的网站带来巨大的冲击。
对此,也有一些人猜测,ChatGPT “使用与在线付费墙移除程序相同的机制”,即“读取 Google 缓存版本”,而该版本没有用于搜索引擎优化的付费墙。
这个也有可能,因为有用户测试,这的确与 ChatGPT 及其处理数据的方式有关,因为在 Bing AI 上尝试同样的方法没有成功。
当用相同的问题问 Bing AI 时,Bing AI 直接拒绝了这一要求,并很快提醒道,它无法提供完整的文章,要求用户打开链接自行阅读。
另一位 Reddit 用户“Red_Laughing_Man”表示,ChatGPT 可能会忽略任何用于在内容顶部放置横幅的付费墙代码,直到有人注册或登录。
AI 背后的版权、道德问题如何解?
毫无疑问,如果 OpenAI 不紧急制止 ChatGPT 造成的“违规”行为,必然会带来一系列的版权问题。
而正因为版权问题,OpenAI 也收到业界越来越多的诉讼,譬如:
上周,16 位匿名人士决定起诉微软和 OpenAI,称这两家公司基于 ChatGPT 的 AI 产品在未获得同意或提供充分通知的情况下,收集并泄露了他们的个人信息,要求索赔 30 亿美元。
另外据路透社报道,代表科幻小说和恐怖小说作家保罗·特伦布莱和小说家莫娜·阿瓦德已经向旧金山联邦法院提起了版权诉讼,他们发现,由于 ChatGPT 可以给出他们的作品摘要,因此这些作品理所当然地被输入到 ChatGPT 使用的机器学习模型中。 他们指控 OpenAI 在未获得作者许可或未向作者付费的情况下,使用受版权保护的书籍作为数据来训练人工智能系统。
截至目前,还没有已对这些案例进行裁决的结果出炉。不过,更多的人同意,这些案件可能通过围绕隐私和版权建立关键的法律先例来重塑人工智能的未来。
值得关注的是,如果法院做出有利于原告的裁决,OpenAI 可能会面临经济处罚。此外,监管机构可能会加强对 OpenAI 的审查,从而导致监管更加严格。
但也有用户担心,针对 OpenAI 的裁决可能会扼杀人工智能创新。如果每次人工智能系统出现问题时,OpenAI 这类公司都会被处以巨额罚款,这可能会阻碍持续创新的进步。
也有人认为监管和问责制度对于确保 AI 的安全开发和秉持正确目的是必要的。
不过就当下而言,一切尚未有定论。目前也尚不清楚 OpenAI 何时恢复该功能,以及将在平台上进行哪些配置更改以防止这种情况再次发生。参考:
https://help.openai.com/en/articles/8077698-how-do-i-use-chatgpt-browse-with-bing-to-search-the-web
https://www.searchenginejournal.com/chatgpt-disables-browse-with-bing/490775/#close
https://www.cnet.com/tech/openai-sued-by-authors-alleging-chatgpt-trained-on-their-writing/
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。