现在 AI 很智能,但是 AI 产品并不智能。ChatGPT 官方聊天页面只有一个输入框,似乎秉承着 “Simple is Better” 的理念,但很多时候并非越简单越好,使用 ChatGPT 经常需要输入相似的提示词,用起来效率极低。
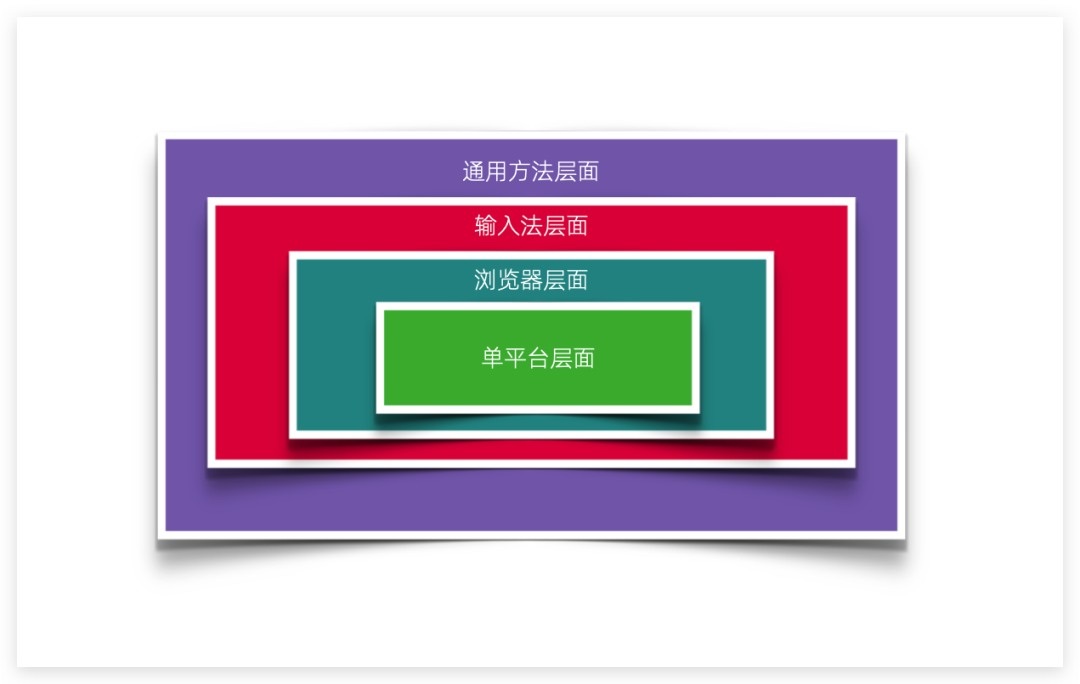
下面将从四个方面简要解释如何通过预定义提示词提高输入效率。
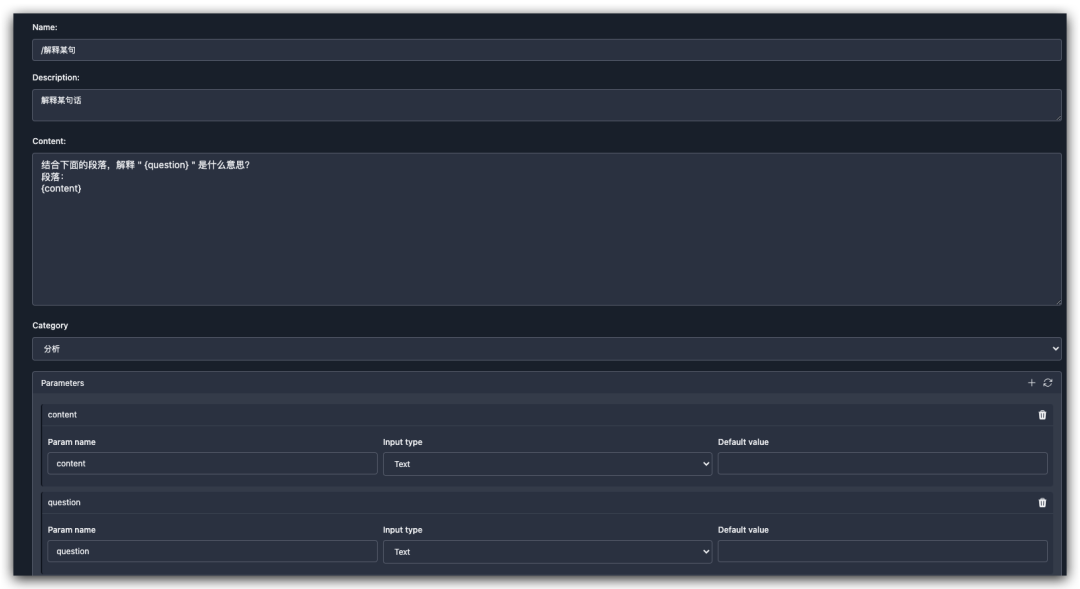
单平台层面,如果你使用 ChatGPT 官网,推荐 ChatGPT Prompt Plus 插件,支持自定义提示词,可以快速呼出,还支持提示词中定义变量,支持为提示词分组,在呼出提示词时选择或者填写即可进行提问,非常方便。下图就是通过该插件预定了 “解释某句” 的界面,可以将需要填写的内容定义为变量,使用时呼出后填充即可。
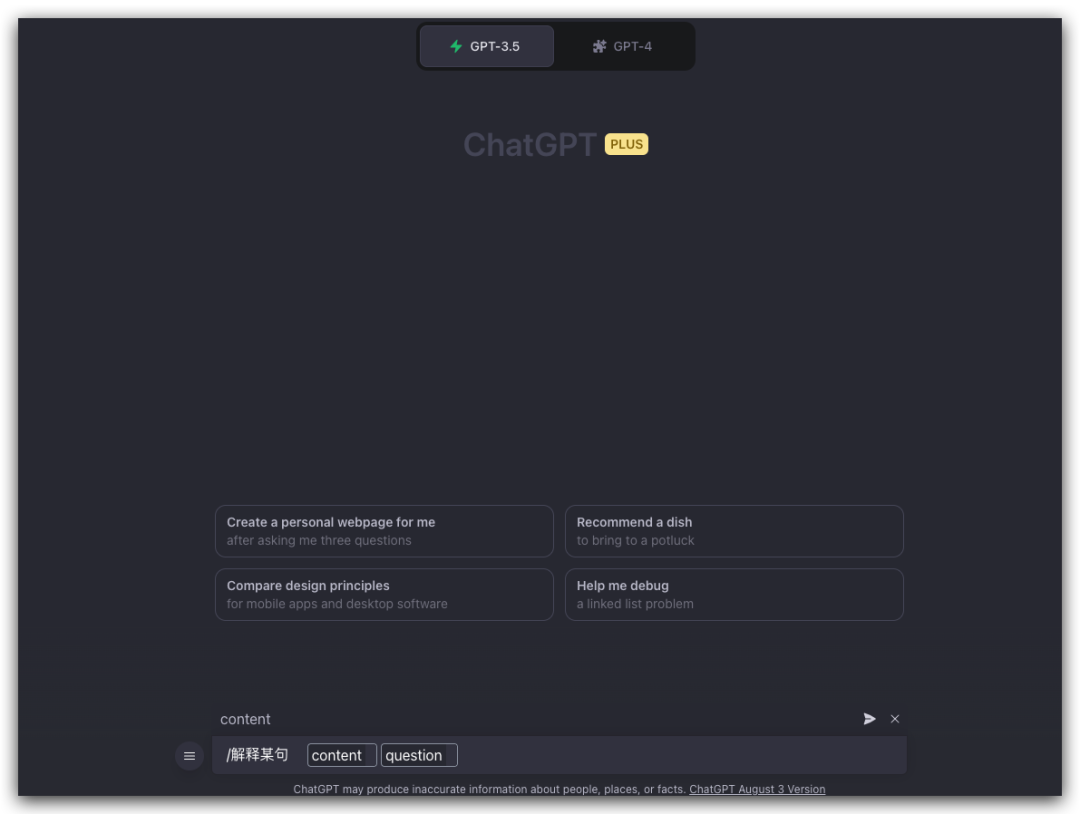
直接通过 “/解释某句” 即可呼出,不需要每次都输入重复的提示词,每次只需要必要的内容,如这里的内容和问题即可自动拼接好提示词发送给 ChatGPT 进行提问。
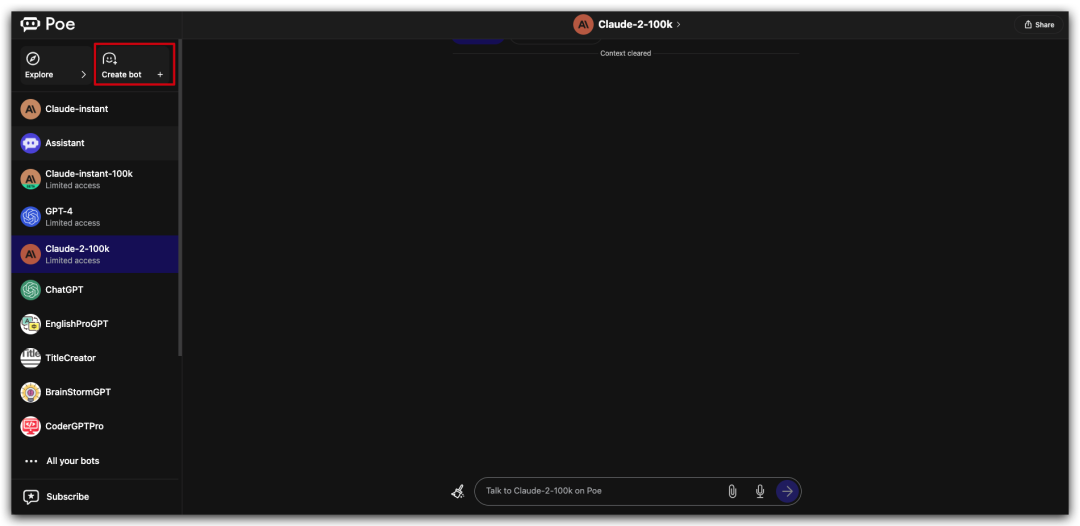
如果你使用 Poe 平台,可以在平台上预定义机器人,具体方法和上面大同小异,感兴趣可以自行研究。
浏览器层面,可以通过安装 ChatGPT Sidebar 这类的 AI 插件,可以在页面上选择一段内容后,直接选择内置或预定义的提示词进行处理即可。

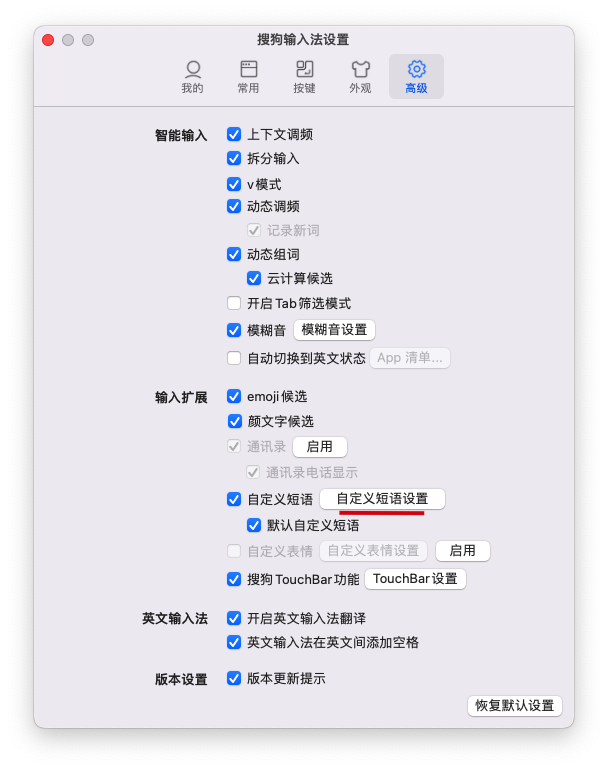
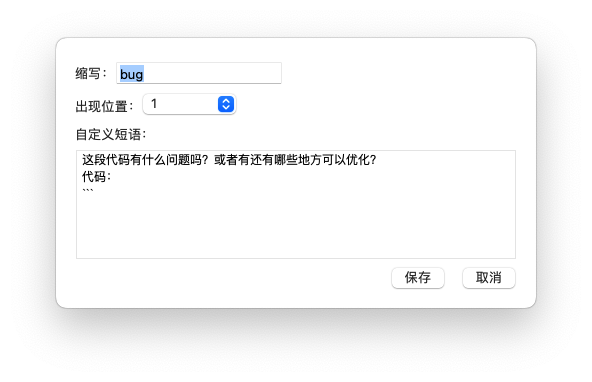
在输入法层面,可以通过自定义短语设置,来预先定义提示词,输入内容时,可以通过输入缩写自动填充提示词。
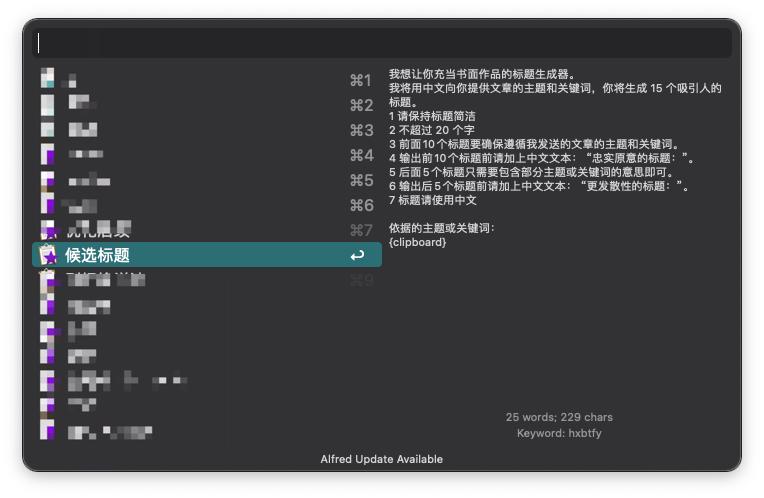
在通用方法层面,你可以利用 Alfred 的 Snippets 功能(支持将剪切板内容作为变量自动替换预定义提示词中的占位符)或者 utools 的备忘功能,来预定义并快速粘贴提示词。
在使用 AI 工具时,如果回答不满意,可以检查自己的提示词是否真正符合“清晰具体、重点突出和充分详尽”的原则。如果调整优化提示词还是得不到想要的答案,可以尝试通过下面的方法解决。
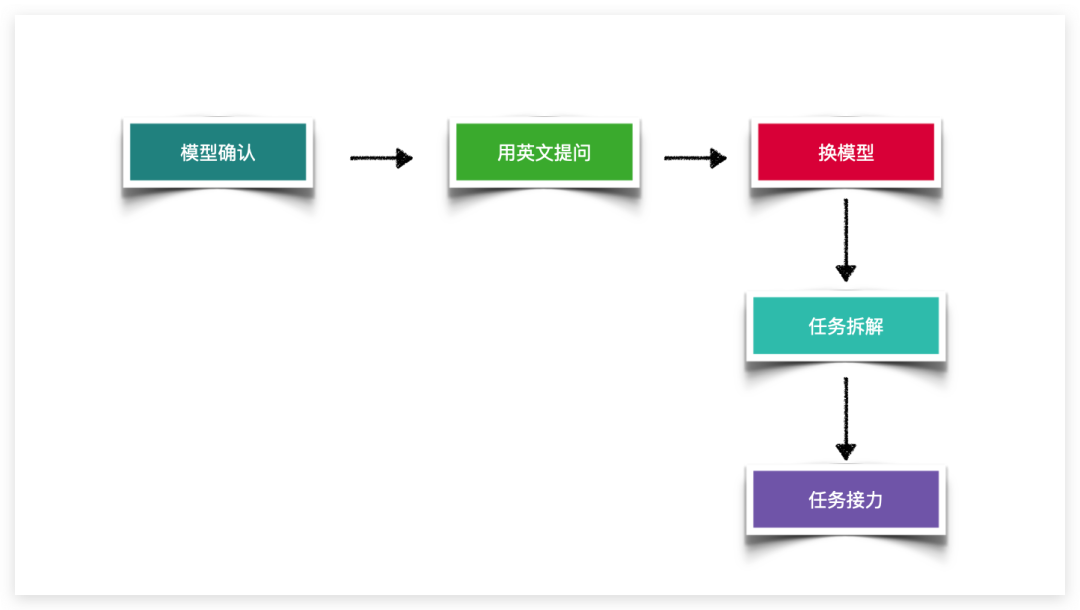
有时候你以为你表达很清楚,其实模型理解和你的表达有偏差,你可以尝试让模型重述你的任务,你可以根据他的重述发现偏差,对提示词进行针对性纠正。
对于提示词并不是很复杂,但是模型似乎不能很好理解你的意图的情况,可以考虑使用英文提问,有时候会有奇效。这可能与模型的语料中英文占比更多,模型更擅长英语有关,也可能是中文提问优先匹配中文语料,但是中文语料质量不高原因导致的。之前就遇到过一个技术问题,用中文对 New Bing 提问很多次都没得到想要的答案,换成英文提问,一次就得到了靠谱的答案的情况。大家如果英文不好,也可以采用“套娃”的方法,如让 ChatGPT 帮你翻译成英文提示词再对 ChatGPT 进行提问。
如果模型理解无误,使用英文提问也没有效果,建议换更高级的模型。在我看来不同的模型就像不同层次的学生,比如有些模型可能是中学生水平,有些模型可能是高中生水平,有些模型则相当于大学生甚至研究生水平。而且不同的模型的擅长之处也有所不同。因此当提示词已经写得很好,但模型回答并不满意时,有条件可以考虑切换到更强大的模型。在我的实际中,能够明显的感觉到 GPT-4 在大多数任务上都会比 GPT-3.5 回答更好,未来或许还会出现更强大的模型。
当使用更高级模型也得不到满意的答案,说明当前任务对大模型来说过于复杂,此时可以考虑任务分解。对于复杂任务,建议大家先进行拆解,拆解到模型比较容易完成的步骤,然后每个步骤让模型去完成,往往效果更好。比如你想让模型写出一个类,可以拆解成不同的函数,然后每个函数让模型去写。
当尝试上述方法还是效果不满意时,可以尝试任务接力。所谓“任务接力”是指,将任务拆解后分步骤让 AI 分步完成或者人与 AI 分工合作完成。比如写代码,你可以开一个对话窗让 AI 写代码,用另外一个对话框让 AI 去找出其中的问题,再让 AI 工具优化代码。比如写稿件,你可以让 AI 写目录供自己参考,也可以让 AI 写草稿自己优化或者你自己直接写稿子,最终再让 AI 去润色。这样复杂任务通过每个步骤拆解成 AI 比较容易完成的粒度或者通过将简单重复的任务分配给 AI ,将复杂 AI不擅长的部分分配给人,可以实现更好地效果。
2.2.4 上下文丢失问题在使用 AI 工具过程中,经过多轮对话之后,你可能会发现模型已经忘了最初的任务是什么。
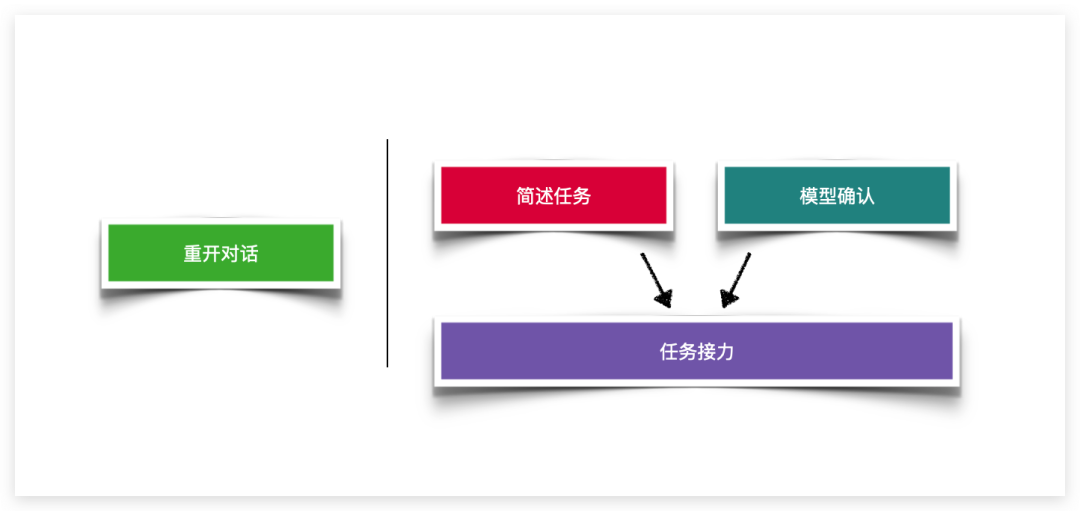
对于这种情况,最简单的处理办法就是重新开一个对话窗口,重新表述问题,继续处理后面的材料。
如果步骤特别多,需要重新开太多对话非常麻烦,可以尝试下面的方法。
前面讲到模型重述任务有助于检查模型是否真正理解任务,在我看来对上下文丢失的问题也有帮助,如果你的任务需要多轮对话才可以完成,可以尝试没隔几轮对话问 AI 任务是什么,通过提醒可以降低“遗忘”的概率。
我在实践过程中经常使用“简述任务”这一方法。例如,当需要让模型概括每个段落的重点时,我会在第一个提示词中详细写明要求。然后,在第二轮发送段落前,我都会重述或简述这个要求。这样即使模型忘记了最初的任务,也能根据第二轮之后的简述完成任务。如“请按照我最初的要求,继续提取下面段落重点发送给我。段落内容:XXX”。
如果模型确认或者简述任务方法还不能解决问题,侧面说明这个任务可能对于模型来说有些复杂了,建议可以将任务进一步拆解,让每一个 Chat 界面只做其中的一个步骤或者有些步骤让 AI 来做,有些步骤让人来完成。
2.2.5 回答可靠性问题很多人用大模型时偶尔会碰到明明回答错误,但是大模型回答的却很有自信的情况,很容易被大模型所“唬住”。
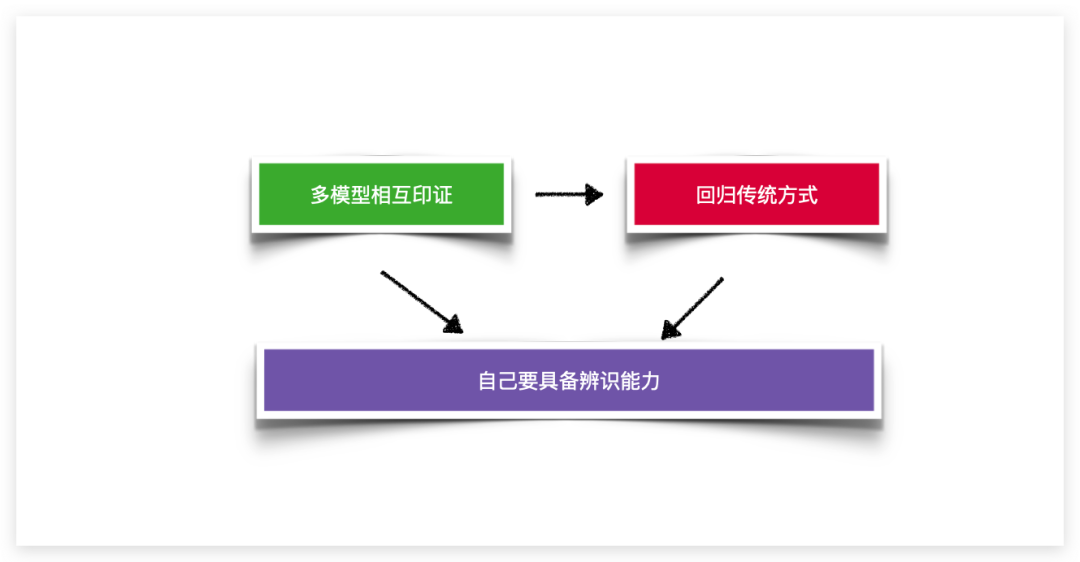
建议对于自己拿不太准的问题可以问多个不同的模型,他们答案之间相互印证,降低都“胡说”的概率。有时,对于相对严谨的内容,可以将 AI 的回答仅作为基本参考,并需结合传统的研究方式,如使用搜索引擎、查阅论文和其他资料等。
最关键的还是自己要具备辨识能力。因为即使不是 AI 时代,你让其他人帮你准备材料,如果你没有足够的辨识度,也很容易出现问题。虽然 AI 能够提高我们的效率,但是我们比以往更需要提高专业素养,提高对信息真伪的辨识能力。
2.2.6 如何更好发收费模型的价值以 ChatGPT 为例, GPT-3.5 目前免费使用, GPT-4 则需要开通 Plus 服务,而且还有每 3 小时 50 个 message 的限制(未来有可能进一步提高,甚至完全放开)。在 Poe 平台上,ChatGPT 和 Claude 也分为免费版和收费版本,收费版也有次数限制。

很多简单的任务免费的模型就可以做的很好,优先可以使用免费模型进行处理。对于复杂的任务,可以安排给收费模型进行处理。
在使用收费模型时,可以将多个步骤合并成一个提示词,节省收费模型的调用次数。
可以使用免费模型产出草稿版本,然后让收费的高级模型进行二次优化,这也是一个不错的选择。
2.2.7 业务接入大模型接入经验现在很多公司开始自研大模型,很多业务也开始接入大模型,下面谈谈业务接入大模型的一些经验,掌握这些经验可以让你少走一些弯路。

大模型不是万能的,我们不应该“为了使用 AI 而使用 AI”。就像汽车虽然方便快捷,但不是在所有情况下都是最佳选择。在实践过程中,我们发现某些任务通过工程化方式解决效果更佳且成本更低。因此,在接入大模型时,我们需要权衡哪些任务适合工程化解决,哪些任务更适合用大模型来解决。
在正式接入模型之前,需要确定模型的效果评估标准,这样才可以发现模型的不足,针对性优化。我们还需要确定可进行工程化开发的前提,比如生成的代码采纳率在 50%,生成的段落达到 80 分以上等。如果我们过早进入工程化开发,产品可能上线后长时间达不到预期标准,甚至可能永远无法达成,从而导致产品可用性较差,并浪费大量资源。
有些复杂任务需要对模型进行微调,需要大量的人工标注,以及评估模型效果工作。为了提高效率,建议大家可以自己编写脚本,或借助 AI 模型进行辅助,实现自动化或半自动化的流程。
在将 AI 模型落地到业务的过程中,开发人员虽然熟悉业务,但可能不了解模型优化的方法;算法人员虽然更专业,却可能对业务不够了解。因此,想要不断优化大模型的效果,就需要开发同学和算法同学通力合作。而且由于有些公司大模型团队的算法人员紧缺,很多业务又想尽早上线,有些开发人员也开始亲自训练大模型。但缺乏专业指导可能会导致许多优化思路不科学,从而会走许多弯路。因此,建议大家在考虑将业务加入 AI 能力,让 AI 为业务提效时,增加算法同学的投入,让算法和开发同学通力合作,更好地解决问题。

或许,提示词只是大语言模型发展早期阶段的一种折中方案。可以类比为汽车的发展,从手动挡逐渐演化到辅助驾驶和自动驾驶,未来我们和大模型的交互可能也会采用更先进的方式,如脑电波、意念等。
虽然 ChatGPT 的出现让人眼前一亮,但是大语言模型还存在很多其他待解决的问题,现在还需要我们去迁就它。
不过,在我看来,这却是一件值得庆幸的事情。正是因为 AI 的不完美,我们才没那么容易失业。
在 AI 发展的当前阶段,我认为最重要的是学好提示词,掌握 AI 工具的最佳实践,才能成为最早一批灵活驾驭大模型来更好解决你生活和工作问题的人,才能在 AI 时代的早期取得一些竞争优势。希望本文提供的一些经验能够让大家少走一些弯路。
你在 AI 工具使用中还有哪些经验?你对当前大语言模型的发展有啥看法?欢迎大家在评论区进行评论补充和讨论。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

