众所周知,⼤模型代表了⼈⼯智能技术的前沿发展。它以强⼤的语⾔理解和⽣成能⼒,正在重塑许多领域。但是从获得⼤模型的 API 接⼊,到将模型应⽤于实际⽣产之间,存在巨⼤的鸿沟,到底要解决哪些问题才能实现真正的跨越?
本文整理自 8 月 12 日「NPCon:AI模型技术与应用峰会」上,来自 Dify.AI 创始人张路宇《LLM 应用技术栈与Agent全景解析》的分享,介绍了当前大模型技术应用技术栈以及 Agent 技术的应用场景和发展趋势。

五、LLMOps 是如何解决这些问题的?
备注:现场视频请查阅「CSDN视频号」,直播回放(56:30处起)

Prompt⼯程化:代码与模型解耦
获得⼀个⼤模型 API 之后,开发者需要通过编写代码对 Prompt 进⾏不断调试和迭代优化。
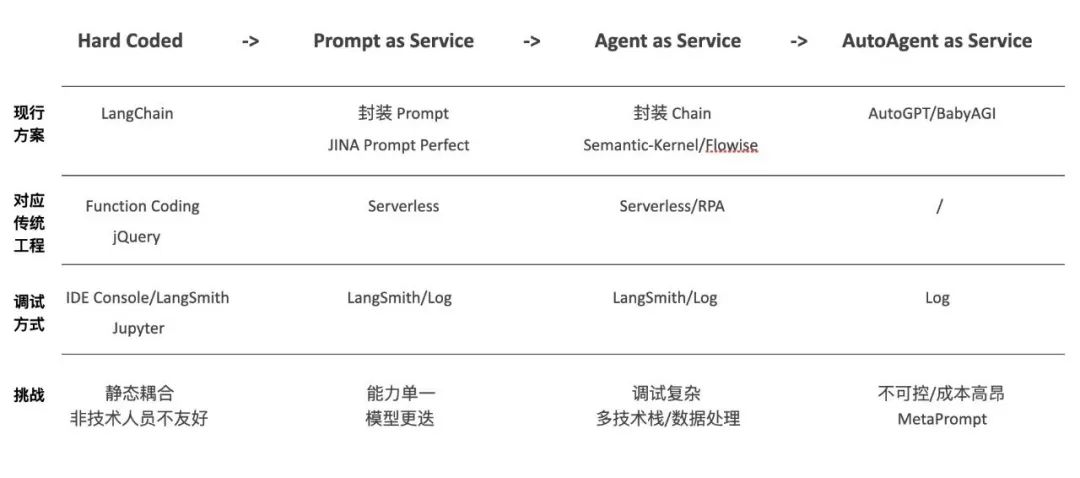 LLM应用工程的演进路线
LLM应用工程的演进路线
但是这种⽅式存在以下两个核⼼问题:
1、Prompt 与代码⾼度耦合。⼀个好的 Prompt 需要⻓时间的调试和优化才能达到预期效果,但与此同时,实现 Prompt 的代码通常很简单,只是起到⼀个逻辑串联的作⽤。这导致 Prompt ⼯程师和开发者的⼯作⽆法有效分离,整个开发过程效率低下。
2、对⾮技术⼈员完全不友好。Prompt 的调试实际上需要语⾔和领域专家进⾏语义上的迭代优化。但是传统的代码开发⽅式将 Prompt 封装在代码逻辑中,使得语⾔专家和⾮技术⼈员⽆法参与 Prompt 开发和优化过程,⽆法发挥他们的专⻓。
这样的开发⽅式导致 Prompt ⼯程很难落地。我们需要实现 Prompt 与代码的解耦,以更好地发挥语⾔专家和⾮技术专家的作⽤,让 Prompt ⼯程像其他软件⼯程流程⼀样实现⻆⾊分⼯、协作开发。同时,我们还需要使⽤更易⽤的界⾯与⼯具,降低⾮技术⼈员的使⽤⻔槛,让他们也能参与 Prompt 开发和持续优化,发挥各⽅的专业价值。

私有化数据接⼊:持续更新与调整
⼤模型都是通过公开可⽤的数据集进⾏预训练的,对单次输⼊⻓度也存在限制,⼀般在 4000 个 Token 左右。这使得开发者⽆法直接利⽤企业内部的专有数据来丰富模型的应⽤语境,构建针对业务场景优化的 AI 应⽤。
要实现私有化数据的有效利⽤存在以下困难:
微调整个模型需要⼤量标注数据、GPU 算⼒和时间成本。这对⼤部分⼈来说不现实也不可⾏。
简单的⽂本匹配⽅式效果很有限。将⽤⼾问题与⽂档⽚段简单匹配,容易产⽣语义偏差,⽆法精准理解⽤⼾意图。
⻓⽂本 Inputs 也难以直接接⼊模型,需要切分嵌⼊。
⽆法进⾏持续数据接⼊和更新,模型语境脱离最新业务。
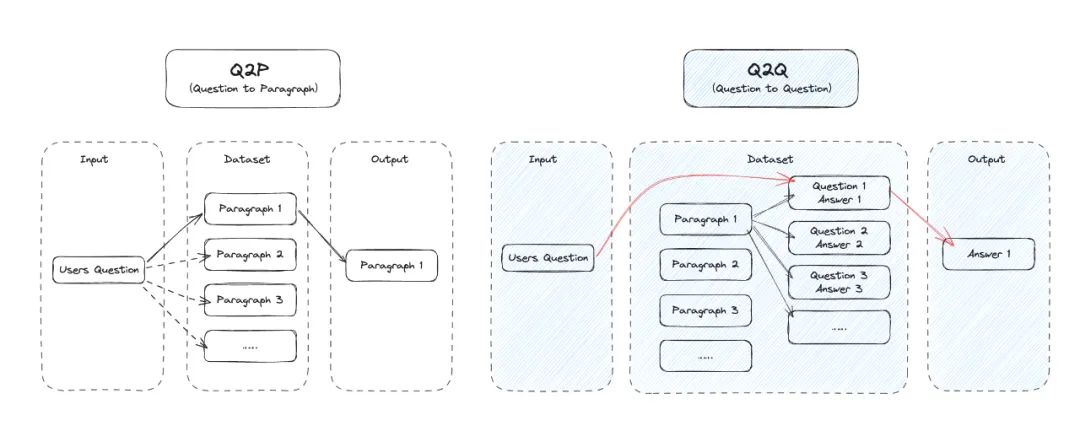
⽐如利⽤问答对进⾏匹配,⽽不是简单的上下⽂⽚段,具体步骤是:
1.使⽤语义匹配技术对⽂档库进⾏划分,⽣成问答对
2.将⽤⼾查询与问答对库匹配,找到匹配程度最⾼的问答对
3.提取该问答对的答案作为回复
这种匹配⽅式充分利⽤了问答对的双向互证关系,能⼤幅提升匹配精确度,使模型理解⽤⼾意图的能⼒上⼀个台阶。与此同时,还需要⾃动化处理⻓⽂本的分割和向量嵌⼊,以便⾼效输⼊模型。
然⽽即使这样⼀个⾮常简单的能⼒,在实际开发中都会有很多⼯程细节。

Agent 的演进:⾃动化编排
AI 提⾼效率的进程,是从辅助你更快地完成⼀件事⸺直接帮你完成⼀件事⸺替代⼀个⼈。也是 Agnet 从纯⼿⼯编排到⾃主编排的演进过程。
要实现⼀个真正智能且⾃动化的 Agent,需要解决多轮复杂对话中的⾃动化推理和执⾏问题。主要⾯临以下挑战:
1、⾃动化规划:分解对话⽬标及完成任务所需的多个步骤,进⾏动态规划。
2、提⾼记忆⼒:合理利⽤⻓期记忆知识库和多轮对话短期记忆,⽽不是单轮独⽴推理。
3、⼯具使⽤:⽆缝调⽤外部⼯具和服务,实现复杂任务⽬标。
4、不断总结反思:关注对话过程,总结经验,改进下⼀轮回复。
5、多轮细致推理:进⾏跨轮的深度推理,⽽不只是浅层次单轮推理。
6、⾏动执⾏:根据推理结果,完成真实世界的任务和⾏动。
要实现这些能⼒,关键是以特定格式组织对话过程,引导模型进⾏结构化推理。包括⽤⼾语句、过往对话记忆、⼯具调⽤以及反思等知识。还需要不断学习和优化这种过程表⽰,以产出更⾼质量的对话与⾏动执⾏。

我们最终会丢掉 LangChain 这本教科书
LangChain 在⼤模型应⽤开发学习中⽆疑是教科书级的存在,它提供了完善的模型连接器、Prompt 模板、Agent 抽象概念等⽂档。但从产品化应⽤⻆度,它也存在⼀些局限:
LangChain 更偏向代码库,与业务系统集成困难,⽆法直接应⽤于产品。
复杂的概念需要⼤量学习成本,⻔槛较⾼。
⼯具集成脆弱,直接应⽤效果有限,模型⽀持存在鸿沟。
缺乏运营管理功能,不适合⾮技术⼈员使⽤。
⽆法进⾏持续优化和数据迭代。
LangChain 让我们充分认识到⼤模型应⽤开发的复杂性。但从代码库到产品,还需要进⼀步的框架和⼯具⽀持。每个⼈都要学习 LangChain,但最终都会丢掉它。

LLMOps是如何解决这些问题的?
⾯对上述种种难题,是否存在⼀个⼯具或平台,可以帮助我们简化基于⼤模型构建应⽤的过程呢?
LLMOps(LargeLanguageModelOperations) 应运⽽⽣。
LLMOps 是⼀个涵盖⼤模型开发、部署、优化等全流程的最佳实践。它的⽬标是通过流程化和⼯具化,简化和降低基于⼤模型应⽤开发的⻔槛,解决数据、Prompt、Agent ⾃动化等难题,使任何组织和开发者都可以⾼效地利⽤⼤模型技术。
⽐如 Dify,它作为 LLMOps 理念的具体实践产品,成功地解决了从⼤模型到实际应⽤之间的鸿沟,实现了理论到现实的转化。
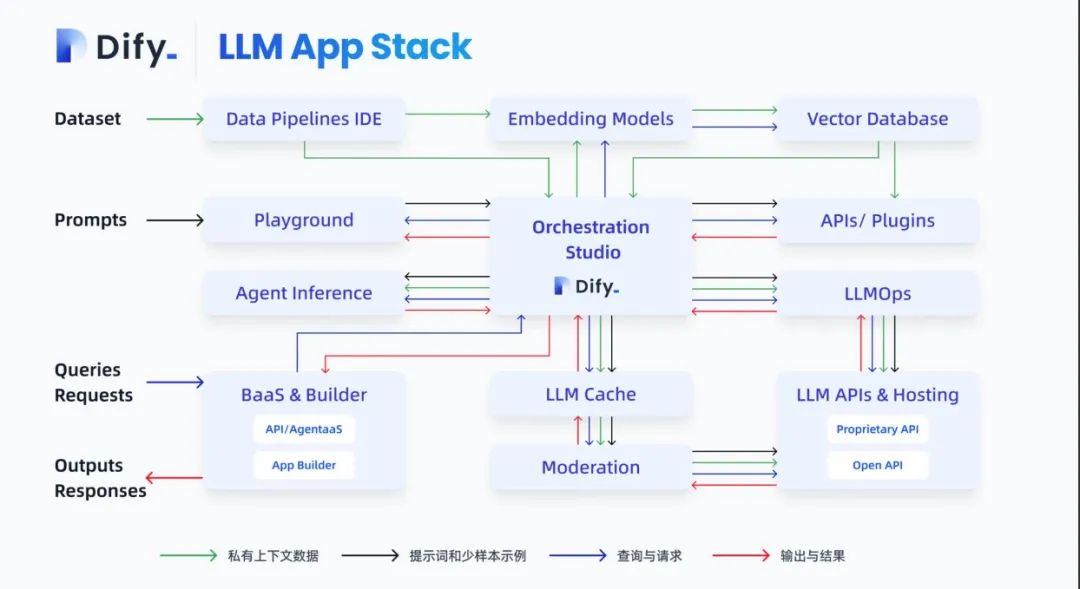
在 Prompt ⼯程化⽅⾯,Dify 通过可视化编辑实现了 Prompt 与代码的解耦,降低了学习⻔槛,提⾼了协作效率,让更多⽤⼾也能参与 Prompt ⼯程。
在私有化数据利⽤⽅⾯,Dify 通过⾃动化的数据处理流程,实现了私有数据的⾼效注⼊,增强了模型的业务适配性。
在 Agent 的⾃动化⽅⾯,Dify 提供了完整的 Agent 构建框架,⼤⼤简化了⾃动化推理系统的开发。

通过 Dify.AI 等 LLMops 开发工具,可以有效解决以下问题:
所⻅即所得的 Prompt ⼯程,⽀持⾮技术⼈员实时调试和优化。
数据 0 代码化准备,⽀持快速数据清洗、分段和集成。
⾃动化⻓⽂本分割、嵌⼊和上下⽂存储。
⼀键应⽤部署,实时监控和⽇志追踪。
国内外多模型可插拔组件化,⽀持GPT、Claude、MiniMax、百川BaiChuan、讯⻜星⽕等,选择更加灵活。
⽀持托管在 HuggingFace 及 Replicate 上的开源模型,如 Llama2。
Agent 实验室:智聊,推出了⽹⻚浏览、Google 搜索、Wikipedia 查询等第⼀⽅插件。并与开发者共建⾃主 Agent、插件开发、多模态等新能⼒探索。
多⼈协作开发和组织管理。
快速对接业务系统,提供 API 接⼝即服务。
LLMOps 正将⼤模型技术从理想主义的概念,逐步引领⾄现实的应⽤落地。它极⼤降低了基于⼤模型应⽤开发的⻔槛,提供了从理论到实践的⽆缝过渡与落地。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

