作者 | 李秋键
出品 | AI科技大本营(ID:rgznai100)
引言:随着深度学习的发展,网络模型的深度也随之越来越深,但随着网络模型深度的加深,往往会曾在这随着模型深度的加大,模型准确率反而下降的问题,而深度残差模型的提出就是为了解决这个问题。
一般来讲,网络的层数越深,提取到的特征越丰富,模型对目标函数的拟合能力越强。但过深的网络容易导致过拟合,且由于梯度消失等问题,深层的网络难以训练。深度残差网络Resnet由卷积神经网络发展变换得来。2015年,由微软研究院Kaiming He等提出的深度残差网络通过引入恒等路径使权重参数有效传递与更新,解决了卷积神经网络层数加深导致的过拟合、权重衰减、梯度消失等问题,性能表现优异。
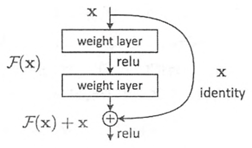
在深层次的网络中训练时,由于反向传播的连乘机制,常常会出现在越靠近输入层的地方出现梯度消失。Resnet将网络结构调整为,将靠近输入层的网络层进行短接到输出层。这样网络就被设计成只需要拟合输入x和目标输出的残差y-x的模型,这也是模型被称为Resnet的原因。这样即使是多加了一层,那模型的效果也不会变差,因为新加的层会被短接到两层以后,相当于是学习了个恒等映射,而跳过的两层只需要拟合上层输出与目标之间的残差即可。
故今天我们将实现python搭建resnet模型辅助我们理解残差网络:
 Resnet基本介绍
Resnet基本介绍
深度残差网络的结构包括输入层、卷积层、多个残差模块、激活函数、批标准化层、全局平均池化层、正则化层和多标签分类层。其中卷积层可以有效地提取特征图的局部特征,减少了可训练的权重参数。卷积层将卷积核与上层输入数据卷积运算后叠加一个偏置,得出的结果经过激活函数计算得到的输出特征值作为下层的输入。批标准化层可以减小样本数据和特征的差异,减轻初始化参数的依赖,使训练的收敛速度更快。其优化了方差的大小和均值的位置,对可训练参数进行正态分布处理并进行归一化处理,使得数据更均匀的分布在0~1,增强了模型的泛化能力。
残差模块的引入有效地解决了深度卷积网络的退化问题,提升模型的特征提取能力。残差模块包含由多层堆叠卷积组成的残差路径和短路路径。由于在卷积运算的过程中不同的卷积步长会改变输出特征图的维度,如果卷积运算没有改变输入特征图的维度,可采用恒等映射型残差模块。恒等映射型残差模块的短路路径将输入特征图恒等输出,并将其与残差路径的输出特征图相加,得到残差模块的输出特征图。如果卷积运算改变了输入特征图的维度,则无法将短路路径和残差路径的输出特征图直接相加,需通过降采样型残差模块,在短路路径上进行1×1卷积运算降采样以保持短路路径与残差路径输出特征图维度相同后,两者方可相加。
(1)Relu缓解的梯度消失和Resnet缓解的梯度消失有何不同?
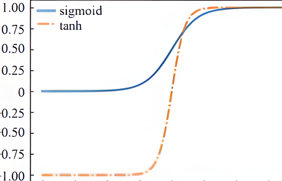
Relu解决的使用sigmoid等激活函数时造成的梯度消失,原因在于sigmoid激活函数值域范围为0到1,当输出值特别大或特别小时,根据图像特点可知此时的梯度接近于0,从而造成梯度消失。而relu激活函数不存在这种情况。
但是即使使用Relu激活函数,当网络层数加深时,多个深度网络反向传播链式传递的多个参数连乘仍然会出现梯度消失。故使用Resnet来改善网络深度造成的梯度消失,使用残差模块和短接模块进行训练,当模型效果已经达到期望值时,使得新加入的层直接学习恒等映射,并不会使得模型效果变差。
(2)Resnet是如何解决梯度消失的?
Resnet将网络结构调整为,将靠近输入层的网络层进行短接到输出层。这样网络就被设计成只需要拟合输入x和目标输出的残差y-x的模型。这样即使是多加了一层,那模型的效果也不会变差,因为新加的层会被短接到两层以后,相当于是学习了个恒等映射,反向传播时对后面的参数依赖减少,使得跳过的两层只需要拟合上层输出与目标之间的残差即可。从而缓解连乘参数多带来的梯度消失问题。
 Resnet模型搭建
Resnet模型搭建
为了从代码层面理解模型,下面用pytorch简单搭建手写字体识别模型。
这里程序的设计分为以下几个步骤,分别为预准备、模型搭建以及训练等几个步骤。
2.1 模型预准备
这里包括的预准备首先包括GPU或CPU训练的选择,迭代次数、batch一次训练样本数,学习率。然后通过pytorch中的transforms对数据变换,包括数据增强和转为Tensor等格式以及读入训练和测试数据等,代码如下:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')num_epochs = 100batch_size = 32learning_rate = 0.001transform = transforms.Compose([ transforms.Pad(4), transforms.RandomHorizontalFlip(), transforms.RandomCrop(32), transforms.ToTensor()])train_datatset = torchvision.datasets.MNIST(root='./data/', train=True, transform=transform, download=True, )test_datatset = torchvision.datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor() )train_loader = torch.utils.data.DataLoader( dataset=train_datatset, batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader( dataset=test_datatset, batch_size=batch_size, shuffle=True)2.2 残差模块
构建残差神经网络模型,与一般神经网络搭建类似,但需要判断输出是否为短接加和。代码如下:
class ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels, stride=1, downsample=None): super(ResidualBlock, self).__init__() self.conv1 = conv3x3(in_channels, out_channels, stride) self.bn1 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(out_channels, out_channels) self.bn2 = nn.BatchNorm2d(out_channels) self.downsample = downsample
def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample: residual = self.downsample(x) out += residual out = self.relu(out) return out
2.3 Resnet模型搭建
构建Resnet整体网络模型。代码如下:
class ResNet(nn.Module): def __init__(self, block, layers, num_classes=10): super(ResNet, self).__init__() self.in_channels = 16 self.conv = conv3x3(1, 16) self.bn = nn.BatchNorm2d(16) self.relu = nn.ReLU(inplace=True) self.layer1 = self.make_layer(block, 16, layers[0]) self.layer2 = self.make_layer(block, 32, layers[1], 2) self.layer3 = self.make_layer(block, 64, layers[2], 2) self.avg_pool = nn.AvgPool2d(8) self.fc = nn.Linear(64, num_classes) def make_layer(self, block, out_channels, blocks, stride=1): downsample = None if (stride != 1) or (self.in_channels != out_channels): downsample = nn.Sequential( conv3x3(self.in_channels, out_channels, stride=stride), nn.BatchNorm2d(out_channels) ) layers = [] layers.append(block(self.in_channels, out_channels, stride, downsample)) self.in_channels = out_channels for i in range(1, blocks): layers.append(block(self.in_channels, out_channels)) return nn.Sequential(*layers) def forward(self, x): out = self.conv(x) out = self.bn(out) out = self.relu(out) out = self.layer1(out) out = self.layer2(out) out = self.layer3(out) out = self.avg_pool(out) out = out.view(out.size(0), -1) out = self.fc(out) return outmodel = ResNet(ResidualBlock, [2, 2, 2]).to(device)
2.4 模型训练
同一般网络模型训练相同,包括数据转为GPU读入格式,模型计算输出,设置损失函数计算损失,梯度置零初始化,误差反向传播和参数更新等,代码如下:
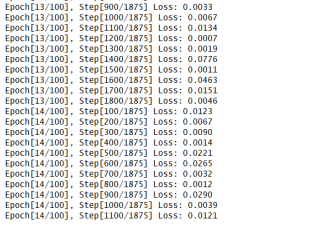
for epoch in range(num_epochs): for i, (images, labels) in enumerate(train_loader): images = images.to(device) labels = labels.to(device) outputs = model(images) loss = criterion(outputs, labels) optimizer.zero_grad() loss.backward() optimizer.step() if (i + 1) % 100 == 0: print("Epoch[{}/{}], Step[{}/{}] Loss: {:.4f}" .format(epoch + 1, num_epochs, i + 1, total_step, loss.item())) losss.append(loss.item())完整代码:
链接:https://pan.baidu.com/s/1PwDHFI70k7pzpMdATulG_g提取码:k2kq
李秋键,CSDN博客专家,CSDN达人课作者。硕士在读于中国矿业大学,开发有taptap竞赛获奖等。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

